By default Castle ActiveRecord eagerly loads your object data. For a small set of connected objects, this default behaviour is fine. The problems start when it is possible to navigate from the object that you have loaded to other potentially large object graphs. As an example let's imagine that we are writing some code to track books in our house. Say I want to track which books I have by author, along with the bookshelf that I'm keeping them on. I'd also like to track chapters of interest and which editions of the book that I have. I also want to tag my bookshelves with keywords describing the types of books on the shelf.
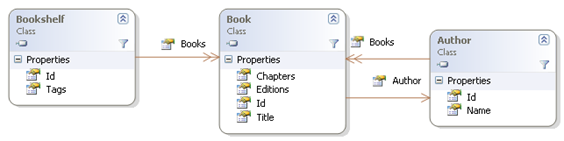
The Bookshelf and the Author classes both contain collections of Books. Nominally, the Author owns the books and the shelf has a reference to the object. I've also decided that I need to navigate bi-directionally between the book and the author classes. Here's a basic implementation using ActiveRecord.
using System.Collections.Generic;
using Castle.ActiveRecord;
namespace BooksAndStuff.Models
{
[ActiveRecord("Bookshelf")]
public class Bookshelf
{
[PrimaryKey(PrimaryKeyType.HiLo)]
public int Id { get; set; }
[HasMany(typeof(string), Table = "Tags", ColumnKey = "BookShelfId",
Cascade = ManyRelationCascadeEnum.AllDeleteOrphan, Element = "TagName",
Lazy = Switches.LazyCollections, BatchSize = Switches.BatchSize)]
public IList<string> Tags { get; set; }
[HasMany(typeof(Book), Table = "Books", ColumnKey = "BookShelfId",
Cascade = ManyRelationCascadeEnum.None,
Lazy = Switches.LazyCollections, BatchSize = Switches.BatchSize)]
public IList<Book> Books { get; set; }
}
[ActiveRecord("Books")]
public class Book
{
public Book() {}
public Book(string title, Author author, string isbn,
IList<string> chapters, IList<string> editions) {
Title = title;
Author = author;
Chapters = chapters;
ISBN = isbn;
Editions = editions;
}
[PrimaryKey(PrimaryKeyType.HiLo)]
public int Id { get; set; }
[Property(NotNull = true)]
public string Title { get; set; }
[HasMany(typeof(string), Table = "Editions", ColumnKey = "BookId",
Access = PropertyAccess.Property, Element = "Edition",
Lazy = Switches.LazyCollections, BatchSize = Switches.BatchSize)]
public IList<string> Editions { get; set; }
[HasMany(typeof(string), Table = "Chapters", ColumnKey = "BookId",
Access = PropertyAccess.Property, Element = "Chapter",
Lazy = Switches.LazyCollections, BatchSize = Switches.BatchSize)]
public IList<string> Chapters { get; set; }
[Property(NotNull = true)]
public string ISBN { get; set; }
[BelongsTo(NotNull = true)]
public Author Author { get; set; }
}
[ActiveRecord("Authors", Lazy = Switches.LazyAuthor, BatchSize = Switches.AuthorBatchSize)]
public class Author
{
[PrimaryKey(PrimaryKeyType.HiLo)]
public virtual int Id { get; set; }
[Property(NotNull = true)]
public virtual string Name { get; set; }
[HasMany(Cascade = ManyRelationCascadeEnum.AllDeleteOrphan,
Lazy = Switches.LazyCollections, BatchSize = Switches.BatchSize)]
public virtual IList<Book> Books { get; set; }
}
public static class Switches
{
public const bool LazyCollections = false;
public const bool LazyAuthor = false;
public const int BatchSize = 1;
public const int AuthorBatchSize = 1;
}
}
I wouldn't normally have a switches class, but it is very useful for the next part. We are going to change the lazy loading and batch size properties of the active record attributes to understand how it influences the way NHibernate fetches the data from the database. To get a feel for the behaviour of NHibernate, we will need some test data. Say that we have a single shelf with 3 books on it, each with a different author. We have another 2 books by one of our authors, but they are not on a shelf (I lent them to Steve).

To test this we need to start up active record:
[TestFixtureSetUp]
public void FixtureSetUp()
{
var connectionString = @"Data Source=localhost;initial catalog=BooksAndStuff;
user=BooksAndStuff_user;password=Password01";
var properties = new Dictionary<string, string>
{
{"show_sql", "true"},
{"connection.driver_class", "NHibernate.Driver.SqlClientDriver"},
{"dialect", "NHibernate.Dialect.MsSql2005Dialect"},
{"connection.provider", "NHibernate.Connection.DriverConnectionProvider"},
{"connection.connection_string", connectionString}
};
var source = new InPlaceConfigurationSource();
source.Add(typeof(ActiveRecordBase), properties);
ActiveRecordStarter.Initialize(source, typeof(BookShelf).Module.GetTypes());
ActiveRecordStarter.CreateSchema();
}
[SetUp]
public void SetUp()
{
ActiveRecordStarter.CreateSchema();
}
This method creates this in the database:
private void GenerateTestData() {
var lewisCarol = new Author {Name = "Lewis Carol"};
var xmasCarol = new Author {Name = "Xmas Carol"};
var luisLuisCarol = new Author {Name = "Luis Luis Carol"};
var chapters = new List<string>{ "Chapter 1", "Chapter 2" };
var editions = new List<string>{"hard back", "spanish"};
var book1 = new Book("Alice in Wonderland", lewisCarol,"xxx-yyy", chapters, editions);
var book2 = new Book("Alice in Wonderland II - Revenge of the Cheshire Cat", xmasCarol,"xxx-yyy", chapters, editions);
var book3 = new Book("Not well known",lewisCarol, "xxx-yyy", chapters, editions);
var book4 = new Book("Not well known either", lewisCarol, "xxx-yyy", chapters, editions);
var book5 = new Book("Some book",luisLuisCarol,"xxx-yyy", chapters, editions);
lewisCarol.Books = new List<Book> {book1, book3, book4};
xmasCarol.Books = new List<Book>{book2};
luisLuisCarol.Books = new List<Book>{ book5 };
var bookshelf = new Bookshelf
{
Tags = new List<string>{"Fantasy", "Old"},
Books = new List<Book> {book1, book2, book5}
};
using (new SessionScope())
{
ActiveRecordMediator<Author>.Save(lewisCarol);
ActiveRecordMediator<Author>.Save(xmasCarol);
ActiveRecordMediator<Author>.Save(luisLuisCarol);
ActiveRecordMediator<BookShelf>.Save(bookshelf);
}
}
Now we have everything in place, we can write a test to load in the data:
[Test]
public void PlayingWithBatchFetchingAndLazyLoading()
{
GenerateTestData();
using (new SessionScope())
{
Console.WriteLine("*******************");
Console.WriteLine("Batch Size:{0} LazyCollections:{1} LazyAuthor:{2}",
Switches.BatchSize, Switches.LazyCollections, Switches.LazyAuthor);
Console.WriteLine("***\nLoading my book shelves");
var shelves = ActiveRecordMediator<Bookshelf>.FindAll();
Console.WriteLine("***\nCounting books on shelf: ");
Console.WriteLine("shelves[0].Books.Count =" + shelves[0].Books.Count);
Console.WriteLine("***\nChecking I have the right book");
Console.WriteLine("\tshelves[0].Books[0].Id:" + shelves[0].Books[0].Id);
Console.WriteLine("***\nCounting the book's chapters");
Assert.That(shelves[0].Books[0].Chapters.Count, Is.EqualTo(2));
Console.WriteLine("***\nHow many books does the first book's author have to his name?");
Assert.That(shelves[0].Books[0].Author.Books.Count, Is.EqualTo(3));
Console.WriteLine("***\nHow many books does the third book's author have to his name?");
Assert.That(shelves[0].Books[2].Author.Books.Count, Is.EqualTo(1));
Console.WriteLine("***\nHow many books does the second book's author have to his name?");
Assert.That(shelves[0].Books[1].Author.Books.Count, Is.EqualTo(1));
Console.WriteLine("***\nWhat is the count of the chapters in a given book?");
Assert.That(shelves[0].Books[0].Author.Books[1].Chapters.Count, Is.EqualTo(2));
Console.WriteLine("***\nHow many chapters does the third book have?");
Assert.That(shelves[0].Books[2].Chapters.Count, Is.EqualTo(2));
}
}
When you run this, you should see the following output from NHibernate:
*******************
Batch Size:1 LazyCollections:False LazyAuthor:False
***
Loading my book shelves
NHibernate: SELECT this_.Id as Id0_0_ FROM BookShelf this_
NHibernate: SELECT books0_.BookShelfId as BookShel5___2_, books0_.Id as Id2_, books0_.Id as Id2_1_, books0_.Title as Title2_1_, books0_.ISBN as ISBN2_1_, books0_.Author as Author2_1_, author1_.Id as Id5_0_, author1_.Name as Name5_0_ FROM Books books0_ inner join Authors author1_ on books0_.Author=author1_.Id WHERE books0_.BookShelfId=@p0; @p0 = '98305'
NHibernate: SELECT chapters0_.BookId as BookId__0_, chapters0_.Chapter as Chapter0_ FROM Chapters chapters0_ WHERE chapters0_.BookId=@p0; @p0 = '65541'
NHibernate: SELECT editions0_.BookId as BookId__0_, editions0_.Edition as Edition0_ FROM Editions editions0_ WHERE editions0_.BookId=@p0; @p0 = '65541'
NHibernate: SELECT books0_.Author as Author__1_, books0_.Id as Id1_, books0_.Id as Id2_0_, books0_.Title as Title2_0_, books0_.ISBN as ISBN2_0_, books0_.Author as Author2_0_ FROM Books books0_ WHERE books0_.Author=@p0; @p0 = '32771'
NHibernate: SELECT chapters0_.BookId as BookId__0_, chapters0_.Chapter as Chapter0_ FROM Chapters chapters0_ WHERE chapters0_.BookId=@p0; @p0 = '65540'
NHibernate: SELECT editions0_.BookId as BookId__0_, editions0_.Edition as Edition0_ FROM Editions editions0_ WHERE editions0_.BookId=@p0; @p0 = '65540'
NHibernate: SELECT books0_.Author as Author__1_, books0_.Id as Id1_, books0_.Id as Id2_0_, books0_.Title as Title2_0_, books0_.ISBN as ISBN2_0_, books0_.Author as Author2_0_ FROM Books books0_ WHERE books0_.Author=@p0; @p0 = '32770'
NHibernate: SELECT chapters0_.BookId as BookId__0_, chapters0_.Chapter as Chapter0_ FROM Chapters chapters0_ WHERE chapters0_.BookId=@p0; @p0 = '65537'
NHibernate: SELECT editions0_.BookId as BookId__0_, editions0_.Edition as Edition0_ FROM Editions editions0_ WHERE editions0_.BookId=@p0; @p0 = '65537'
NHibernate: SELECT books0_.Author as Author__1_, books0_.Id as Id1_, books0_.Id as Id2_0_, books0_.Title as Title2_0_, books0_.ISBN as ISBN2_0_, books0_.Author as Author2_0_ FROM Books books0_ WHERE books0_.Author=@p0; @p0 = '32769'
NHibernate: SELECT chapters0_.BookId as BookId__0_, chapters0_.Chapter as Chapter0_ FROM Chapters chapters0_ WHERE chapters0_.BookId=@p0; @p0 = '65539'
NHibernate: SELECT editions0_.BookId as BookId__0_, editions0_.Edition as Edition0_ FROM Editions editions0_ WHERE editions0_.BookId=@p0; @p0 = '65539'
NHibernate: SELECT chapters0_.BookId as BookId__0_, chapters0_.Chapter as Chapter0_ FROM Chapters chapters0_ WHERE chapters0_.BookId=@p0; @p0 = '65538'
NHibernate: SELECT editions0_.BookId as BookId__0_, editions0_.Edition as Edition0_ FROM Editions editions0_ WHERE editions0_.BookId=@p0; @p0 = '65538'
NHibernate: SELECT tags0_.BookShelfId as BookShel1___0_, tags0_.TagName as TagName0_ FROM Tags tags0_ WHERE tags0_.BookShelfId=@p0; @p0 = '98305'
***
Counting books on shelf:
shelves[0].Books.Count =3
***
Checking I have the right book
shelves[0].Books[0].Id:65537
***
Counting the book's chapters
***
How many books does the first book's author have to his name?
***
How many books does the third book's author have to his name?
***
How many books does the second book's author have to his name?
***
What is the count of the chapters in a given book?
***
How many chapters does the third book have?
Blimey - that was a lot of SQL! 16 Select statements. Also, notice how it was all executed on the initial load of the Bookshelf. The logic for loading ran something like this:
- Load all the data from the Bookshelf table for all the bookshelves
- For each bookshelf
- Load in all the data from the books and authors table for each book on the shelf and its corresponding author
- For each book on the shelf
- Load all the Chapters for the first book on the shelf
- Load all the editions for the first book in the shelf
- For each author
- Load all the data from the books table for the author
- Repeat the book loading logic for every book belonging to the author which was not on the shelf
- Load in all the tags for the shelf
All that so that we can ask for the first shelf. We haven't even begun to touch the object yet. Why did NHibernate do this? All of these objects can theoretically be reached from the bookshelf. Because we may want to touch any of these objects after we have retrieved the BookShelf from the database, NHibernate decided it better go and grab the lot so that we could get to these objects if we had to. This is eager loading, and is the default behaviour of ActiveRecord unless you explicitly instruct it otherwise. Notice also, that we have an N+1 selects problem too. There is a single select statement being issued for every collection for every object. This is a a very expensive way to fetch data from the database.
The key to optimising the fetch behaviour is how you use the the Lazy and BatchSize properties of the various ActiveRecord attributes.
Removing N+1 Select with BatchSize
The BatchSize property can be used on collections or on ActiveRecord classed directly. When you use the setting on a collection, NHibernate will attempt to populate the collection for [BatchSize] of the objects which NHibernate is aware of an has not populated yet.
We'll start by adding batching
public static class Switches
{
public const bool LazyCollections = false;
public const bool LazyAuthor = false;
public const int BatchSize = 2;
public const int AuthorBatchSize = 10;
}
Batch Size:2 LazyCollections:False LazyAuthor:False
***
Loading my book shelves
SELECT this_.Id as Id3_0_ FROM BookShelf this_
SELECT books0_.BookShelfId as BookShel5___2_, books0_.Id as ...
SELECT chapters0_.BookId...WHERE chapters0_.BookId in (@p0, @p1); @p0 = '65541', @p1 = '65540'
SELECT editions0_.BookId...WHERE editions0_.BookId in (@p0, @p1); @p0 = '65541', @p1 = '65540'
SELECT books0_.Author...WHERE books0_.Author in (@p0, @p1); @p0 = '32771', @p1 = '32770'
SELECT chapters0_.BookId...WHERE chapters0_.BookId=@p0; @p0 = '65537'
SELECT editions0_.BookId...WHERE editions0_.BookId=@p0; @p0 = '65537'
SELECT books0_.Author...WHERE books0_.Author=@p0; @p0 = '32769'
SELECT chapters0_.BookId...WHERE chapters0_.BookId in (@p0, @p1); @p0 = '65539', @p1 = '65538'
SELECT editions0_.BookId...WHERE editions0_.BookId in (@p0, @p1); @p0 = '65539', @p1 = '65538'
SELECT tags0_.BookShelfId...WHERE tags0_.BookShelfId=@p0; @p0 = '98305'
***
That improved the behaviour somewhat. We're down to 11 statements. NHibernate is now resolving the objects in the collections 2 at a time. This is not very useful as we typically have more than 2 books on a shelf, so we have 2 trips round the loop to load in all the data for our shelf. If we up the BatchSize to 5 we can get everything in 7 statements:
Batch Size:5 LazyCollections:False LazyAuthor:False
***
Loading my book shelves
SELECT this_.Id as Id3_0_ FROM BookShelf this_
SELECT books0_.BookShelfId...WHERE books0_.BookShelfId=@p0; @p0 = '98305'
SELECT chapters0_.BookId..WHERE chapters0_.BookId in (@p0, @p1, @p2); @p0 = '65541', @p1 = '65537', @p2 = '65540'
SELECT editions0_.BookId...WHERE editions0_.BookId in (@p0, @p1, @p2); @p0 = '65541', @p1 = '65537', @p2 = '65540'
SELECT books0_.Author...WHERE books0_.Author in (@p0, @p1, @p2); @p0 = '32771', @p1 = '32769', @p2 = '32770'
SELECT chapters0_.BookId...WHERE chapters0_.BookId in (@p0, @p1); @p0 = '65539', @p1 = '65538'
SELECT editions0_.BookId...WHERE editions0_.BookId in (@p0, @p1); @p0 = '65539', @p1 = '65538'
SELECT tags0_.BookShelfId...WHERE tags0_.BookShelfId=@p0; @p0 = '98305'
***
Bear in mind that the BatchSize only influences how many of the objects which will be populated in the current known set of objects. In the example above, even though we only have 5 books we still have make two trips to the database to load all the books in. The first time NHibernate decides it needs to load in a Book is when it loads the shelf. At this point in time, there are only 3 known books so they are fetched. Later on, while loading in the authors, the 2 remaining books are identified and fetched in a second batch.
Using Lazy Loading
The biggest problem with the fetch patterns above is the large amount of data being retrieved which may not be required. This is potentially very wasteful. Lazy loading allows you to control this. With our current object model, it probably doesn't make sense to always pull in the author (and the related books of the author) every time we load a bookshelf. How about we look at the results of lazy loading the author.
public static class Switches
{
public const bool LazyCollections = false;
public const bool LazyAuthor = true;
public const int BatchSize = 5;
public const int AuthorBatchSize = 10;
}
*******************
Batch Size:5 LazyCollections:False LazyAuthor:True
***
Loading my book shelves
SELECT this_.Id as Id3_0_ FROM BookShelf this_
SELECT books0_.BookShelfId... WHERE books0_.BookShelfId=@p0; @p0 = '98305'
SELECT chapters0_.BookId ... WHERE chapters0_.BookId in (@p0, @p1, @p2); @p0 = '65541', @p1 = '65537', @p2 = '65540'
SELECT editions0_.BookId ... WHERE editions0_.BookId in (@p0, @p1, @p2); @p0 = '65541', @p1 = '65537', @p2 = '65540'
SELECT tags0_.BookShelfId ... WHERE tags0_.BookShelfId=@p0; @p0 = '98305'
***
Counting books on shelf:
shelves[0].Books.Count =3
***
Checking I have the right book
shelves[0].Books[0].Id:65537
***
Counting the book's chapters
***
How many books does the first book's author have to his name?
SELECT author0_.Id ... WHERE author0_.Id in (@p0, @p1, @p2); @p0 = '32769', @p1 = '32770', @p2 = '32771'
SELECT books0_.Author ... WHERE books0_.Author in (@p0, @p1, @p2); @p0 = '32771', @p1 = '32769', @p2 = '32770'
SELECT chapters0_.BookId ... WHERE chapters0_.BookId in (@p0, @p1); @p0 = '65539', @p1 = '65538'
SELECT editions0_.BookId ... WHERE editions0_.BookId in (@p0, @p1); @p0 = '65539', @p1 = '65538'
***
How many books does the third book's author have to his name?
***
How many books does the second book's author have to his name?
***
What is the count of the chapters in a given book?
***
How many chapters does the third book have?
This has dramatically changed the way we retrieve data from the database. Now we do not load any of the books which are not on the shelf until we touch the author property of the book. The initial load is much cheaper, although we still pull in a load of data which is not required. How about we lazy load the collections as well?
*******************
Batch Size:5 LazyCollections:True LazyAuthor:True
***
Loading my book shelves
NHibernate: SELECT this_.Id as Id3_0_ FROM BookShelf this_
***
Counting books on shelf:
SELECT books0_.BookShelfId... WHERE books0_.BookShelfId=@p0; @p0 = '98305'
shelves[0].Books.Count =3
***
Checking I have the right book
shelves[0].Books[0].Id:65537
***
Counting the book's chapters
SELECT chapters0_.BookId... WHERE chapters0_.BookId in (@p0, @p1, @p2); @p0 = '65537', @p1 = '65540', @p2 = '65541'
***
How many books does the first book's author have to his name?
SELECT ... WHERE author0_.Id in (@p0, @p1, @p2); @p0 = '32769', @p1 = '32770', @p2 = '32771'
SELECT books0_.Author... WHERE books0_.Author in (@p0, @p1, @p2); @p0 = '32769', @p1 = '32770', @p2 = '32771'
***
How many books does the third book's author have to his name?
***
How many books does the second book's author have to his name?
***
What is the count of the chapters in a given book?
NHibernate: SELECT chapters0_.BookId... WHERE chapters0_.BookId in (@p0, @p1); @p0 = '65538', @p1 = '65539'
***
How many chapters does the third book have?
As you can see, the up front cost of loading the bookshelves is now very cheap, we are progressively loading in data as we touch more and more of the object graph. I would suggest that this is generally the best behaviour. In this case we never retrieve the tags or editions from the database because we don't touch them. If another method wants to load a bookshelf to edit its tags, we won't incur the cost of loading all the books on the shelf (and there could be 100's of those).
In summary, I'd recommend that you default to setting Lazy loading and batch fetching for all collections and consider lazy loading large aggregate classes - such as the Author in this example, so that you don't inadvertently pull out huge chunks of the database. Also, keep watching your SQL output by setting show_sql to true now and again. Quite innocent seeming changes to your domain model can quickly magnify the number of objects that can be navigated to from another domain object. If you don't have a Lazy constraint between your objects to act as an NHibernate firebreak, then you will cause the amount of SQL issued to increase dramatically.
Don't forget that lazy loading can only work when you remain inside the hibernate session. If you detach your object from the session then you will get a LazyInitializationException thrown when you attempt to access a collection of object that has not been initialised.